
Exposing Dockerized AI Models via RESTful API
24/05/2021 - Technology
Here we expose inference NLP models via Rest API using Fast API and Gunicorn with Uvicorn worker.
Introduction
Container technologies, such as Docker, simplify dependency management and improve portability of your software. In this series of articles, we explore Docker usage in Machine Learning (ML) scenarios.
This series assumes that you are familiar with AI/ML, containerization in general, and Docker in particular.
In the previous article of this series, we have run an inference model for NLP using models persisted on a Docker volume. In this one, we’ll expose the above model as a service using Fast APIand Gunicorn. You are welcome to download the code used in this article.
Why Fast API?
At the moment, Flask is the king of Python Rest API services. However, Fast API is quickly gaining momentum. While Flask with all its plugins is hard to beat in flexibility, Fast API is much faster and simpler to use in most common scenarios. Additionally, it comes with native support for asynchronous communication and OpenAPI.
Deploying Fast API
Unlike Flask, Fast API doesn’t include even a simple development server. The third-party option recommended for it is Uvicorn. Uvicorn on its own lacks many features you would expect from a production server, such as scaling the number of running processes or automatic restart of failed workers. To handle such scenarios, Fast API is often used together with Uvicorn workers managed by Gunicorn. While this arrangement seems somewhat complex, it is very easy to implement. This is the one we’ll use in this article.
Container Definition
Our Dockerfile will be very similar to the one from the previous article. The only three statements that are different appear bolded in the code below:
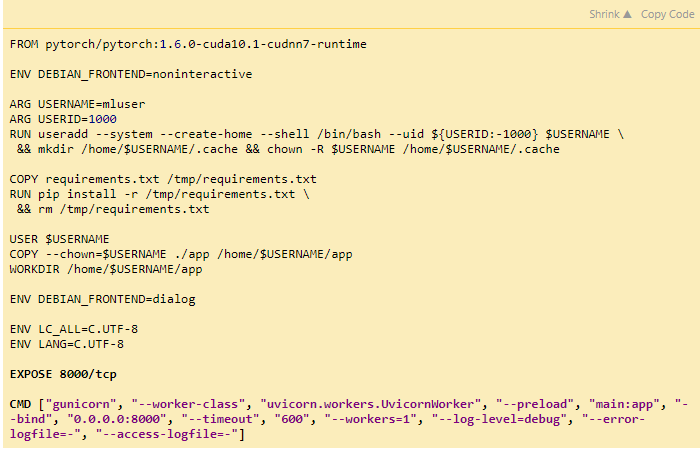
In the RUN useradd statement, we have added a seemingly redundant default value for USERID. We’ll explain this when we discuss the docker-compose configuration.
In the last two statements, we document exposing port 8000 for TCP protocol and add a command to start our service using Gunicorn. Note the 10 minutes timeout. It may seem like overkill, but it is only to ensure enough time to download a model to Docker volume the very first time an API method is executed.
Note that we request only a single worker here (argument --workers=1). You may increase this value to handle multiple concurrent requests. However, remember that each worker will load a separate model copy to memory. Unfortunately, because running inference on a model is a CPU-bound task, there is no way to benefit from parallel asynchronous processing within a single worker.
We need a few new libraries in our requirements.txt file in addition to the ones we’ve used previously:

API Application
Before continuing, download the source code for this article. The model-related code is included in the app/nlp_service.py script, and the API code – in the app/main.py script.
Now, to expose our question-answer model via a Rest API, all we need to do is include the following code in the app/main.py:

While this is not a “single line of code” simple, it should be easy to understand. We import the required libraries, define classes for request and response, initialize the FastAPI application, and finally expose a single API method, question_answer. Let’s try it out in action.
Building Container Image
As in the previous article, we’ll use docker-compose. This time, with the following docker-compose.yml:

The differences from the previous article are bolded. The new build args USERID value, which is used during the build, corresponds to the new user section at the end, which will be used when our container is running. We use environment variables for USERID and GROUPID this time because we want to run our service using the docker-compose up command, which is better suited for long-running services than the simple run. Believe it or not, there is no argument to pass user context directly for docker-compose up.
The port section ensures proper port mapping between the container and the host when the container is running.
With all the pieces in place, we can finally build our image:

Like before, you can skip the USERID and GROUPID values when running on Windows – the default values defined in the Dockerfile will be used. And this is exactly the reason why we needed to change the following line in the Dockerfile:

With our current docker-compose.yml, when no USERID variable is defined, the empty USERID value would be passed to the build process. With --uid ${USERID:-1000}, we ensure that the default value of 1000 will be used.
Running Container
When our environment variables are defined and the image is successfully built, we can start it:

After a few moments, we should see a confirmation that our Gunicorn server is ready to accept requests:

Testing API
Now we can check our service. Because Fast API supports OpenAPI, we can do it in a web browser by entering the following local address:


To run semantic analysis, we simply click the selected method and then the Try it out button:

Then, we can enter our text directly into the Request body field and click the Execute button below:

When the request is completed, we can scroll down to the results:

Mission accomplished! Feel free to experiment with the remaining methods. Remember that the very first time you use a new method it will download its own model. This can take a while before you get a response in such a case.
Limitations
Now we have a Rest API service with our Transformers NLP models. Note that not always what can be done should be done. The Transformers models are very heavy, slow and, in general, they are much better suited for batch processing than for ad-hoc web requests.
When exposing these models via a Rest API, you need to account for timeouts and ensure enough RAM for each worker to load their own model(s) into memory.
Additionally, our API service is not designed to be exposed directly to internet traffic. In its current form, with no security measures such as authentication, authorization, or CORS, it should be kept behind a firewall for trusted system-to-system communication.
If needed, FastAPI natively supports OAuth2. However, we like to keep services with our models as thin as possible, with additional layers to handle security or any other business logic. If interested, have a look at this article for an example of how you can reliably expose large (and slow) Transformers models to the internet.
Summary
In this article, we’ve used Fast API to run inference on our NLP models via a web browser. Our code is becoming more and more complex though, so pretty soon we’ll need to debug it. In the next article, we’ll do exactly that. We’ll use Visual Studio Code to edit and debug code running inside a Docker container. Stay tuned!
[Nguồn:https://www.codeproject.com/Articles/5302894/Exposing-Dockerized-AI-Models-via-RESTful-API]
 Sidecar packages, deploys, and executes AWS Lambda functions from your Laravel application.
Sidecar packages, deploys, and executes AWS Lambda functions from your Laravel application.
24/05/2021 - Technology

